Bengali Handewritten Graphemes detection
Tushar Dhyani
Understanding the problem
Automatic handwritten character recognition (HCR) and optical character recognition (OCR) are quite popular for commercial and academic reasons. For alpha-syllabary languages this problem increases manifolds due to its non-linear structure. Bengali, a member of alpha-syllabary family, is way trickier than English as it has 50 letters - 11 vowels and 39 consonants - plus 18 diacritics. This means there are roughly 13,000 ways to write Bengali letters, whereas English only has about 250 ways to do the same. This huge number of combinations makes recognizing Bengali characters a lot harder. These different elements has been shown below for a visual understanding.


Different vowel diacritics (green) and consonant diacritics (red) used in Bengali orthography. The placement of the diacritics are not dependent on the grapheme root.
we have the following distribution of graphemes in Bengali.
Number of unique grapheme roots: 168
Number of unique vowel diacritic: 11
Number of unique consonant diacritic: 7
Solutions
To create a mixture of different roots, I followed a unique augmentation technique - cut-mix. This technique involves randomly cutting and mixing parts of different images while training. But, as a native speaker of the same family of language, I knew that there were some specific ways to achieve this. This way involves having specific class in a specific zone. From this, I devised this zone structure and did a cut-mix augmentation while training my model. The specific zones are showcased below:
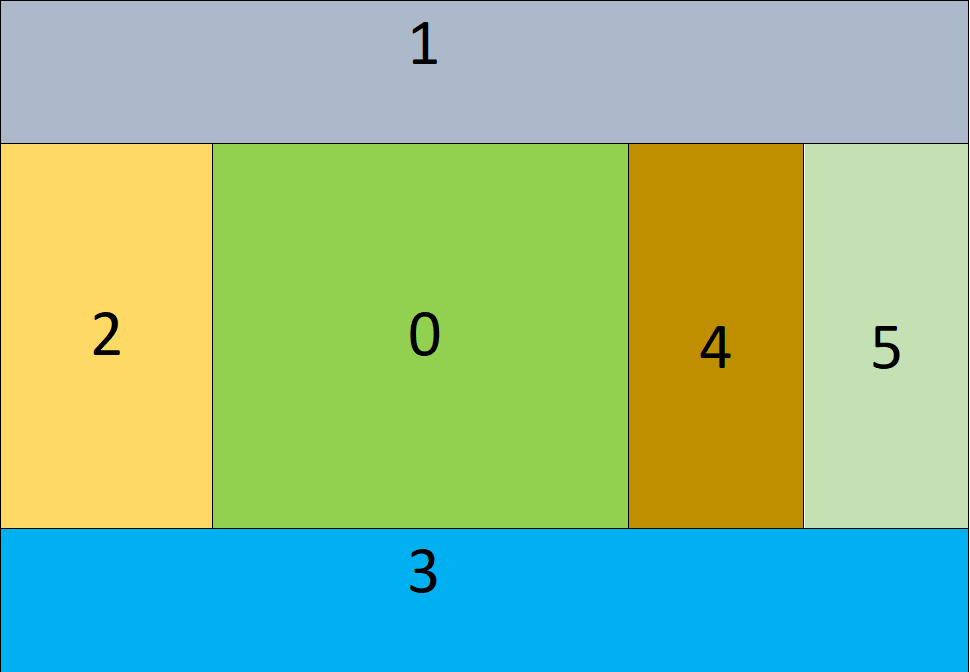
Based on the rough distribution of the zone, I mixed respective parts to create augmentations that sometimes resembled real and sometimes unreal examples. The process could be understood from the picture below how this structure helped increase the training data distribution.
_yOZI9EEOR.webp?updatedAt=1702421988334)
Sadly this process didn't work directly, because the mistakes and unrealistic images are too much noise for the model to deal with. I was able to tone down the noise by doing the following tricks - The grapheme root zones are roughly correct most of the time, while the vowel and consonants are way off. I figured that since grapheme root and consonant 3 and 6 are the main classes to tackle, I should focus on those.
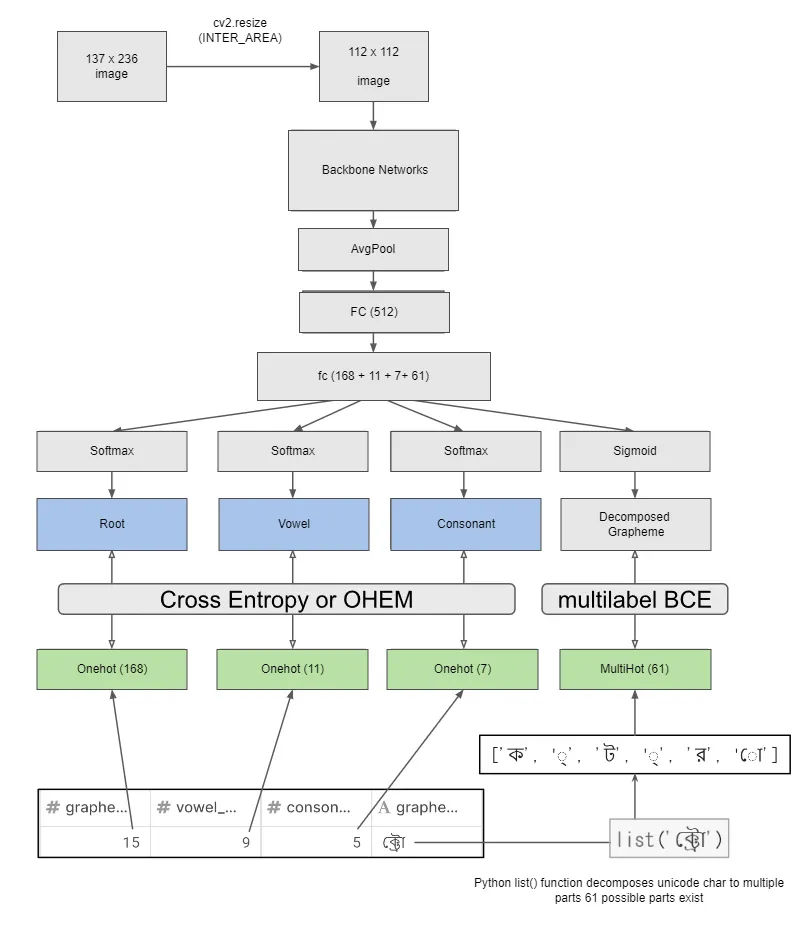
My training pipeline roughly looked as follows:
Results
Models are evaluated using a hierarchical macro-averaged recall. First, a standard macro-averaged recall is calculated for each component (grapheme root, vowel diacritic, or consonant diacritic). The final score is the weighted average of those three scores, with the grapheme root given double weight.
| Model name | Validation score | Public score | Private score | |||
| Root | Vowel Dicritic | Consonant Dicritic | Overall | |||
| EfficientNet B1 | 0.971 | 0.988 | 0.978 | 0.977 | 0.9638 | 0.9385 |
| EfficientNet B2 | 0.921 | 0.978 | 0.987 | 0.952 | 0.9615 | 0.9245 |
| Resnet18 | 0.951 | 0.982 | 0.978 | 0.966 | 0.9599 | 0.9223 |
Score on the leaderboard
With the best backbone model that I had, I scored 55 on the private leaderboard and scored my first silver medal.
