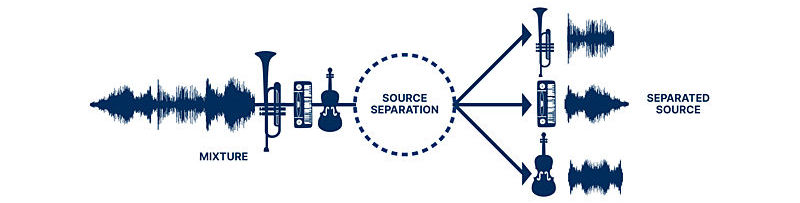
Separating different sounds in a recording is called sound separation. In this project, I focused on just two uses: music and movies. When it comes to music, sound separation means pulling out voices and instruments from a song. For example, let's break down the parts of two songs that I found randomly. Thanks to the creators.
A little detailed scientific report on this project is available on Researchgate. Please feel free to read and share your feedback with me over email
Emotion analysis primarily focuses on classifying, predicting and retrieving emotions and their related properties from text. However, only few research was conducted towards analyzing the semantic roles of emotions, i.e. who is experiencing which emotion, what caused it and what or whom is it directed towards. This project investigate the influence of semantic role labels on emotion role prediction. Building on top of previous approaches and resources, I've implemented a framework for predicting emotion roles using different features with co-researcher Maximilian Wegge. We find that semantic role label features have no significant influence on the task and identify two possible reasons for that.
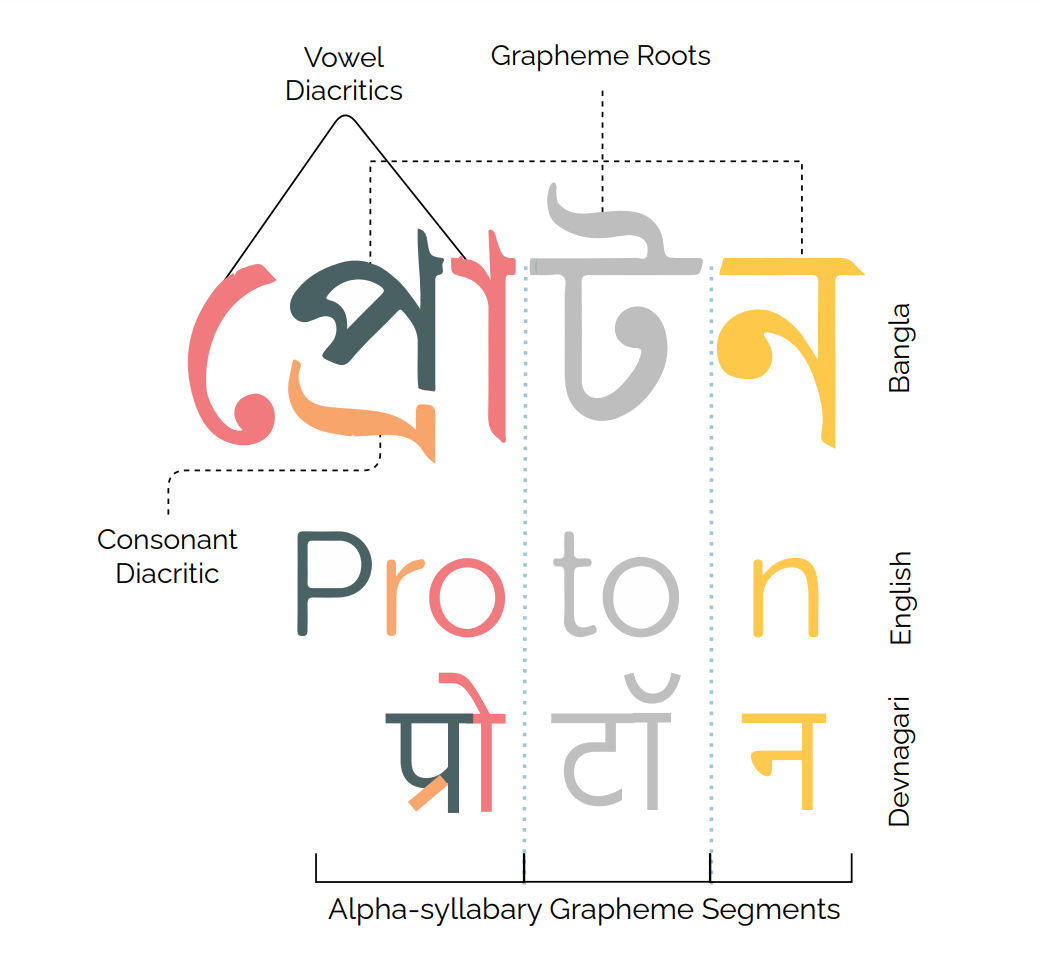
Automatic handwritten character recognition (HCR) and optical character recognition (OCR) are quite popular for commercial and academic reasons. For alpha-syllabary languages this problem increases manifolds due to its non-linear structure. Bengali, a member of alpha-syllabary family, is way trickier than English as it has 50 letters - 11 vowels and 39 consonants - plus 18 diacritics. This means there are roughly 13,000 ways to write Bengali letters, whereas English only has about 250 ways to do the same. This huge number of combinations makes recognizing Bengali characters a lot harder. These different elements has been shown below for a visual understanding.
This research has been made available on Researchgate. You can also send me a request over personal email to access a pdf copy of the report if you encounter some issues with the link above.
Audio recordings in the real world are typically tainted by noise and other distortions. These distortions come from many factors such as environmental noises, and distortions from various kinds of electronics, circuits, and microphones. These noises and distortions cause issues during the perception of speech to the receiver. This project tries to provide a solution to the problem of noise in speech using a generative approach and compares the effectiveness of the generative approach over other existing approaches.
A primary focus lies in developing machine learning models capable of detecting toxicity within online discussions. Toxicity, in this context, refers to anything perceived as rude, disrespectful, or potentially causing someone to exit a conversation. Typically, toxicity is categorized using binary classification, but this approach limits the ability to discern the severity of toxic comments. In my project for a Kaggle competition, I present a system aimed at addressing this limitation.