Sound demixing challenge
Tushar Dhyani
Problems:
This project was a part of Sound demixing challenge organized by Sony on AIcrowd. The report to this challenge is available here.
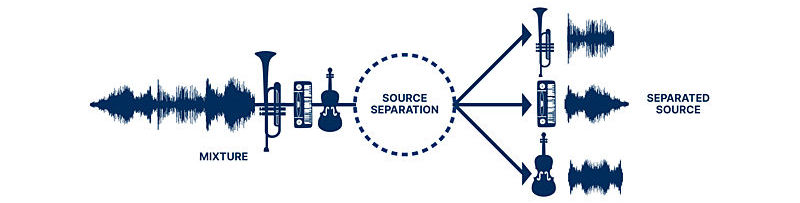
Separating different sounds in a recording is called sound separation. In this project, I focused on just two uses: music and movies. When it comes to music, sound separation means pulling out voices and instruments from a song. For example, let's break down the parts of two songs that I found randomly. Thanks to the creators.
| Source | Sound demixing sample | Sound demixing sample |
|---|---|---|
| Mixture | ||
| Vocals | ||
| Drums | ||
| Bass |
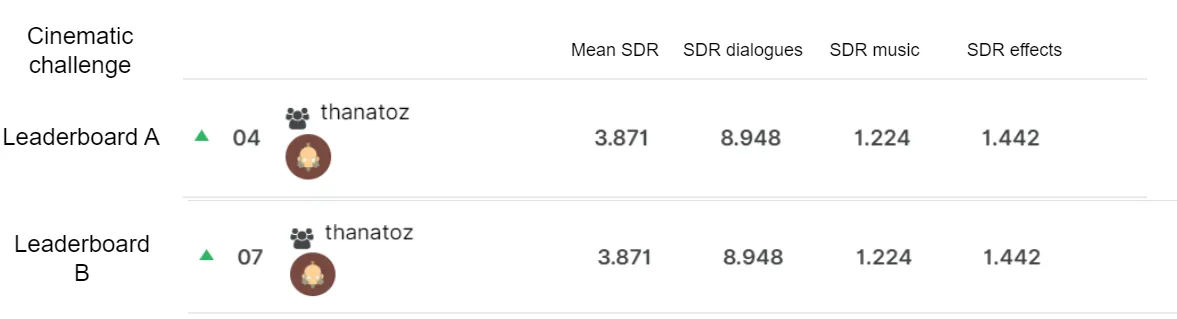
The challenge was broadly divided into two tracks: Music demixing (MDX) and Cinematic sound demixing (CDX) but the aim was still similar. The complexity of the problem lay in sub-problems: Labelling noise (leaderboard A), Bleeding in recording (Leaderboard B) and General source separation (Leaderboard C). But due to contraints with time and training resources, I decided to stay with the general source separation.
Method
This was one of the most interesting challenges that I worked on in some time. The challenge here was not to find the available research as there were quite a few that I was already aware of, but to find resources to train the model. For this, the university student resources were very helpful, so thanks to the university student body for that.
So, for the challenge, I decided to train the availble models with some modification that I will be elaborating later. But overall the idea was to find an optimal way to train the models for each track.
I started infering the available pretrained models. For my experiments I used the following available resources.
- Demucs v{1,2,3,4}
- MDXnet
- ByteSep
- Danna-sep
Based on a my validation dataset, I found ByteSep to be the perfect candidate for training.
After checking for data consistency, I
Rankings:
So after the challenge, the final standing of my model were as follows for each track