Speech enhancement on mel-spectrogram using denoising diffusion probablistic models.
Tushar Dhyani, Yung-Ching Yang
Institut für Maschinelle Sprachverarbeitung, University of Stuttgart
This research has been made available on Researchgate. You can also send me a request over personal email to access a pdf copy of the report if you encounter some issues with the link above.
Introduction
Audio recordings in the real world are typically tainted by noise and other distortions. These distortions come from many factors such as environmental noises, and distortions from various kinds of electronics, circuits, and microphones. These noises and distortions cause issues during the perception of speech to the receiver. This project tries to provide a solution to the problem of noise in speech using a generative approach and compares the effectiveness of the generative approach over other existing approaches.
A recent outbreak of generative models has pushed their capacity to generate high-fidelity data and one crucial class of such generative models is Diffusion models. Diffusion models, inspired by thermodynamic diffusion, are generative models that learn generation by learning to denoise diffused images. This could be an oversimplified explanation of an extremely convoluted approach in generative models. To understand diffusion, try to comprehend the image below.

How diffusion works.
Let's start by looking into the image and avoiding all the surrounding text and maths. What you see on the farthest left is a spectrogram of speech. (If you are unaware of what a spectrogram is, try reading about it or watching this simple video). For simplicity, let us consider the spectrogram to be an image or maybe simply consider any image in its place. As we move from the left end to the right, we see that noise is getting added to the image at every step. This process of adding noise is called diffusion. Diffusion destroys the image at every step by adding more and more noise. We train a model to learn to remove this induced noise from the image and generate the real image again. This process of removing noise is denoising. When the number of steps of diffusion and denoising are increased and a model is trained for a really large number of steps, it becomes better and better at this.
How this project solves the issue
We saw how diffusion models work above. If we relate the diffusion process to the actual noise introduction in the real world in audio files or speech signals, we can understand the core idea behind this project. We train a diffusion model to learn denoising the spectrograms and generate the speech signals well. This cannot be achieved without conditioning the spectrograms on real-world images.
What are the application
During the rise of virtual meetings and conferences, all of us have understood the importance of clean speech. These generative networks could play a vital role in receiving high-fidelity speech signals on the receiver's end and have completely noise-free communication. Apart from that, they can also play a critical role in systems generating audio output such as Text-to-speech and give high-fidelity output. One such pipeline has been shown in the image below:
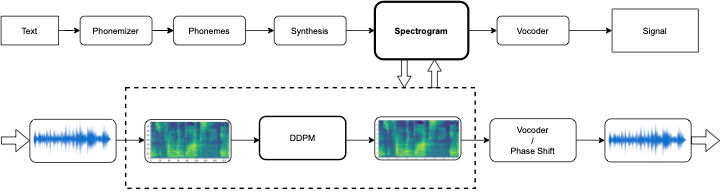
This research is still underway. To read more about it and access my early report, you can send me a request over email.