Jigsaw toxicity detection
Problem
A primary focus lies in developing machine learning models capable of detecting toxicity within online discussions. Toxicity, in this context, refers to anything perceived as rude, disrespectful, or potentially causing someone to exit a conversation. Typically, toxicity is categorized using binary classification, but this approach limits the ability to discern the severity of toxic comments. In my project for a Kaggle competition, I present a system aimed at addressing this limitation.
Method
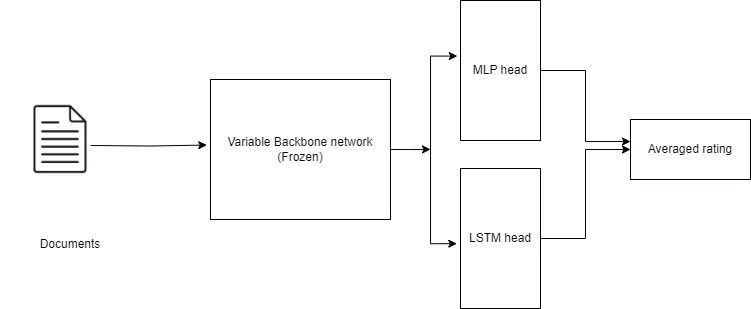
My final solution was weighted average of 8 models:
- BERT Base Uncased
- BERT Base Cased
- BERT Large Uncased
- BERT Large Cased
- BERT Large Uncased WWM
- BERT Large Cased WWM
- BiLSTM with FastText and Glove
- GPT-2 Large
Data: I trained all final models except LSTM on 95% of data, leaving 5% as cold holdout for validation. Final LSTM was trained on full dataset. For my LSTM I used standard cleaning and preprocessing. All other models were trained on RAW data: no cleaning, no preprocessing, no feature engineering. Well, I guess future is now…
Loss: I used weighted sigmoid cross-entropy loss (torch.nn.BCEWithLogitsLoss) with different sets of weights and target variants (including 6 additional toxicity subtypes).
The training and inference pipelines for my model training is as follows: